How often should you forecast?
How often should you be updating forecasts or making new ones? The answer depends on what you mean by “forecast” and can range from “as often as possible” through to something much less frequent.
When you use machine learning to make a forecast there are three parts to it:
- The model
- The parameters
- The data
Making changes to any these could be called “forecasting”.
The three categories are a little bit fuzzy. For example it isn’t totally clear what the boundary is between parameters and model but the basic idea is that you can make very frequent updates for things near the bottom of the list and should be a bit more cautious with things at the top of the list.
This might be easier to understand with an example:
An easy way to make a forecast that includes weekly seasonality is to make the forecast for the next day a weighted sum of the previous seven days. By giving more weight to what happened seven days ago you will see a weekly pattern in the forecast.
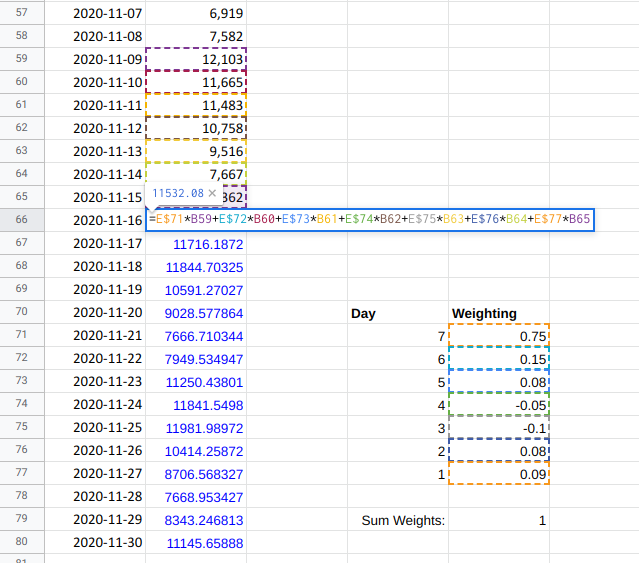
In this example the model is the formula
=E$71*B59+E$72*B60+E$73*B61+E$74*B62+E$75*B63+E$76*B64+E$77*B65 (and similar
in all the other prediction cells), the
parameters are the model weights (in cells E71:E77) and the data is everything
in cells B2:B65.
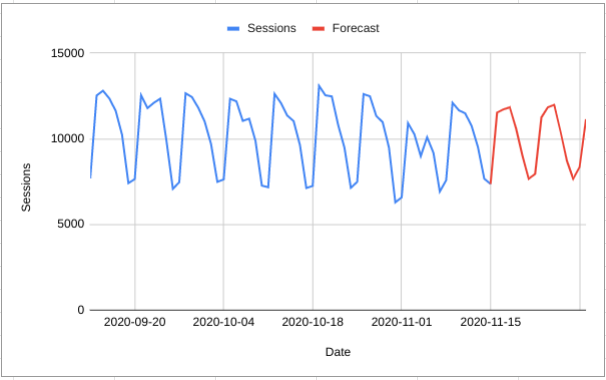
When you get an extra day of data (i.e. every day) you can update the forecast whilst keeping the model and parameters exactly the same:
If (and this is a big if) you believe in the model then there is absolutely no problem with this kind of daily update in the forecast; in this example the model says that “if you have an unusually low or high day then this should make a big change in the forecast”. You might disagree and not want to change the forecast very much based on what could be a random fluke but if you believe that they you need a different model that can take that kind of thing into account.
You can think of machine learning as a process from going from a model and some
data to the parameters that make the model best fit the data. For example, we
could use machine learning to find the optimal values of the parameters in cells
E71:E77 which give the forecast the best accuracy on the training data.
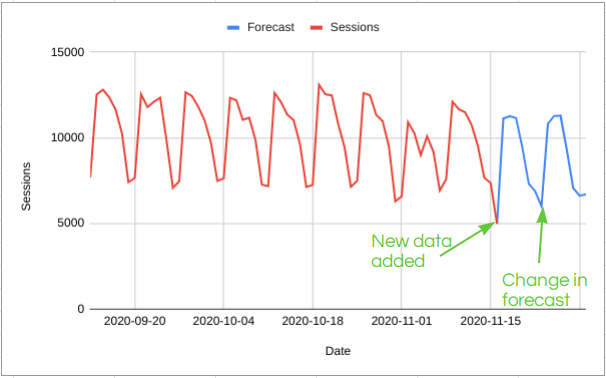
It would also be possible to optimise the parameters after each new day of data. In the above example, this might look a bit like this:
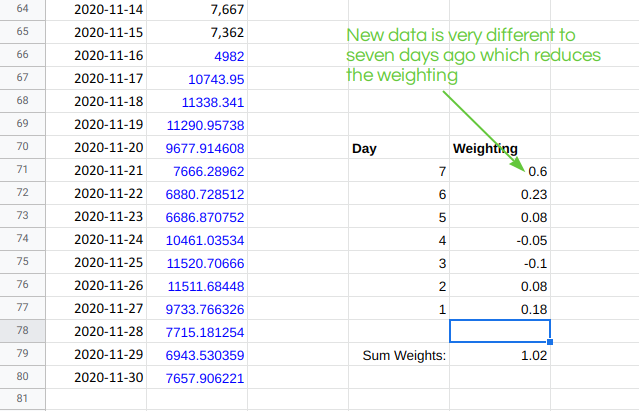
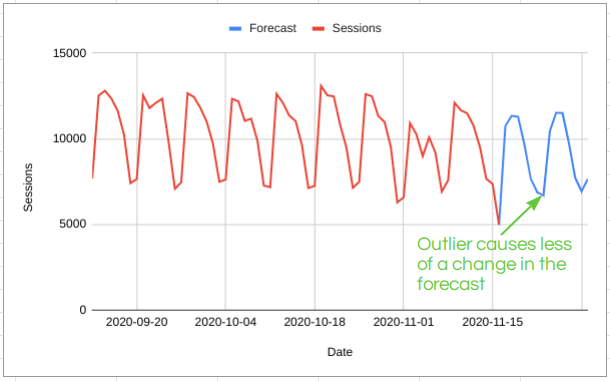
In this case, updating the model parameters (the weights) as new data comes in looks like it might actually be helpful and protect us from a bit of random variation. But there are also risks to this approach.
I’ll illustrate this with a different model:
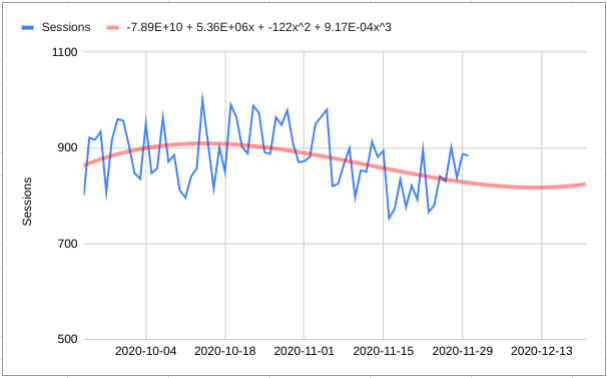
Here the forecasting model is quite different to the previous one; we fit a cubic polynomial on the training data and then use that to predict the future [please do not do this at home].
The predictions this model makes are completely unaffected by adding new data - the polynomial coefficients stay the same and this is the only thing the prediction depends on.
But if we also update the model parameters as new data comes in something like this can happen:
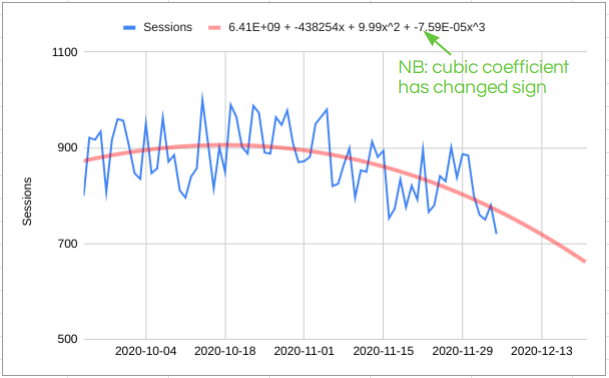
On the scale of the above chart this doesn’t look like a nuclear change, but if you extrapolate the forecast out then 7 days of extra data has changed things from “we are going to take over the world” to “going broke before Christmas”. So the impact of updating the model parameters is either that the forecaster loses all credibility or a complete change in business strategy; I think neither of these is a good thing!
How frequently you can update the data and model parameters depends a lot on the type of model you are using. Ideally you want a model that you can update frequently because recent data has information in it that should be useful for making predictions. But you also want these predictions to be stable when there are small changes in the data.
This is one reason why Forecast Forge doesn’t fit multiple different models and then return a forecast for the one that works best on the historical data. Often different models can be very close on this measure so the best model could change every day as new data comes in - and then the forecast could change a lot too. Better forecast accuracy is traded against higher career risk for my users! If you want to play around with this kind of process then checkout ForecastGA by JROakes which I’m proud to have helped contribute to.
The model used by Forecast Forge is more similar to the cubic model where, once the parameters are learned during training, adding in new data won’t change the forecast; the only way for the forecast to change is if the parameters are updated with new training data.
This means that Forecast Forge has the same weakness as the cubic interpolation model in that training with new data can drastically change the forecast output BUT there are a couple of things that stop is going from “take over the world” to “grab what you can in the firesale”:
- The model is split into seasonal, regression and trend components. Of these three, by far the most important for longer term predictions is the trend and Forecast Forge is setup that it needs to see a lot of evidence before it will forecast a big change in trend. A trend that is small and positive might switch to one that is small and negative but you won’t see a large positive trend switch to a large negative trend without some crazy changes in data that persist for a long period of time.
- The trend component is restricted to being linear (piecewise linear to be precise). This means that a change in trend won’t accelerate away the way the cubic trend did. NB. It is possible to have a trend that accelerates away if you use data transformations - but this is not the default
This means you will be fine to update a preconfigured Forecast Forge forecast every day if you want to; there will only be a big change in the forecast if there are also big changes in the data.
“preconfigured” is doing quite a lot of work in that sentence; one of the features of Forecast Forge is that you can use data transforms and regressor columns to make your forecast better. Changing which transforms or which regressors you use can make a hugely different forecast - if you change these every day then you could definitely fall into the same trap that the cubic interpolation leads to.
All the forecast settings (e.g. country holidays), regressor columns and transformations together make up the model for a forecast. This should not be changed very often. Instead the update cadence should be based on business planning cycles or similar; every quarter or every six months spend some time working on making the best forecast you can using all the regressor and transform tricks you can think of. And then don’t touch these settings again until the next time to review comes around.
A quick aside about regressor columns here: I think it is absolutely fine to change the future values of regressor columns when planning for different scenarios. But what those columns mean and the values in the training data should be fixed.
Update the forecast as new data comes in but don’t casually change the forecast model; this is a piece of work that should be done more carefully and deliberately because the consequences (for what your forecast predicts) can change a lot as a result.
There is still room for a lot of human judgment here; I think that you should probably have updated your forecasts in April 2020 regardless of whatever your commercial timetable might have been!
Forecast Forge is just part of a spreadsheet; I’m not you’re Dad and this is all just advice - do what you think best with it.