Measuring the impact of Google's Title Rewrite Change
Background
On 24th August 2021 Google announced a change in how page title’s would be
displayed in search
results.
The new system means that Google’s machine learning systems will more often
display a custom page title in the links on a search engine results page; before
there was less rewriting being done and the contents of the <title> tag was
more likely to be used.
Barry Schwartz has written a good summary of the ins and outs of this over at Search Engine Land.
As with any algorithm change, Google are saying that this improves results overall but there are some people for whom the new titles seem to be performing significantly worse.
If something is a lot worse or better than it was previously then you don’t need fancy statistics to be able to see that.
But if the change is small and the data you are looking at is noisy then it can be very hard to tell whether something has really happened or not. Especially when there are all kinds of other things going on at the same time!
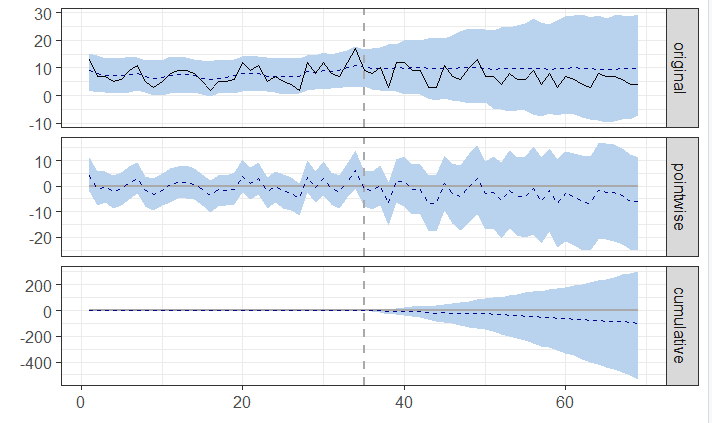
And this situation is very common! But all these small changes can add up to something big or they can be indicative of future trends so it is still important to be able to say whether or not something is actually going on.
Why not just compare before/after or year over year?
Comparing (for example) the 30 days after a change with the 30 days before or with the same 30 days from a year can work really well for answering this kind of question. But being able to make this kind of comparison relies on a few assumptions that don’t always hold true.
- If the business is growing then the more recent data will look better than the older data. So you need the metric in question to be relatively static over time. This is the advantage of making an immediate before/after comparison rather than looking at year over year figures.
- You need to adjust for seasonality; this is less of a problem for a year over year comparison but it can still be an issue; for example your “control” data from last year may contain Easter or a bank holiday which is not part of the more recent “test” data.
- You will be quite lucky if nothing else is different between your two comparison periods. Perhaps one had a large discount and high stock levels. Perhaps there was a fluke viral instagram post.
It is possible to make adjustments for all these things; you might not use machine learning to do so, but this is basically the kind of thing that Forecast Forge is doing automatically in the background when making a forecast. And then, of course, you also have a forecast model that you can use for other things when you’ve finished!
Comparing with a forecast
The big idea here is that you can build a forecast based on data up until the date of the change (24th August in this case - although this is only the date on which the change was announced) and then compare what your forecast says should have happened in the subsequent days with what actually happened. If there is a difference then you can have quite a lot of confidence that something changed on the date in question.
All of this depends on being able to make a good forecast. In an imaginary world with no algorithm change, your forecast would have to be quite close to what actually happened. The better your forecast is then the smaller a change you will be able to detect using this method.
My last post goes through some ideas to help you know if your forecast is good or not. Assuming you have a good one then you can compare the forecast with what actually happened.
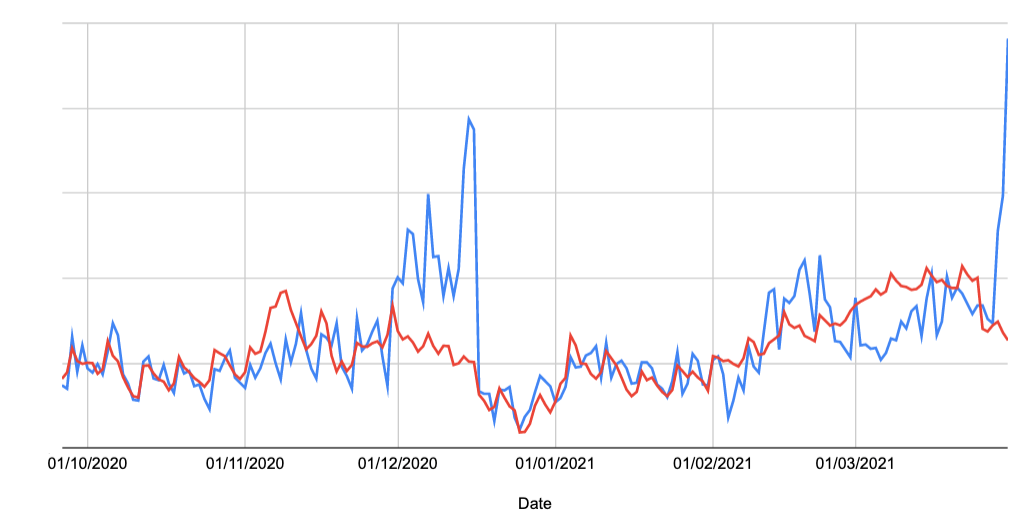
How do you decide whether or not a change is positive and meaningful. In the above example there are some days when the forecasted values are higher and some days when the actual values are higher; this will almost always be the case unless the change you are trying to measure is large or your forecast is very good.
For things like the Google title tag changes stakeholders won’t care that performance is better on 38.2% of days or that the new title display performs worse on Mondays when Jupiter is in Gemini. Instead they want to know whether or not the change is better overall.
In some ways, this is an impossible question to answer because we can’t know how title display will change in the future or even how your current titles will perform next month as search intent in your market changes - after all, you have no historical data on this.
A more defined question is something like this: “So far, are we doing better or worse than in the counter-factual world where the change didn’t happen?”
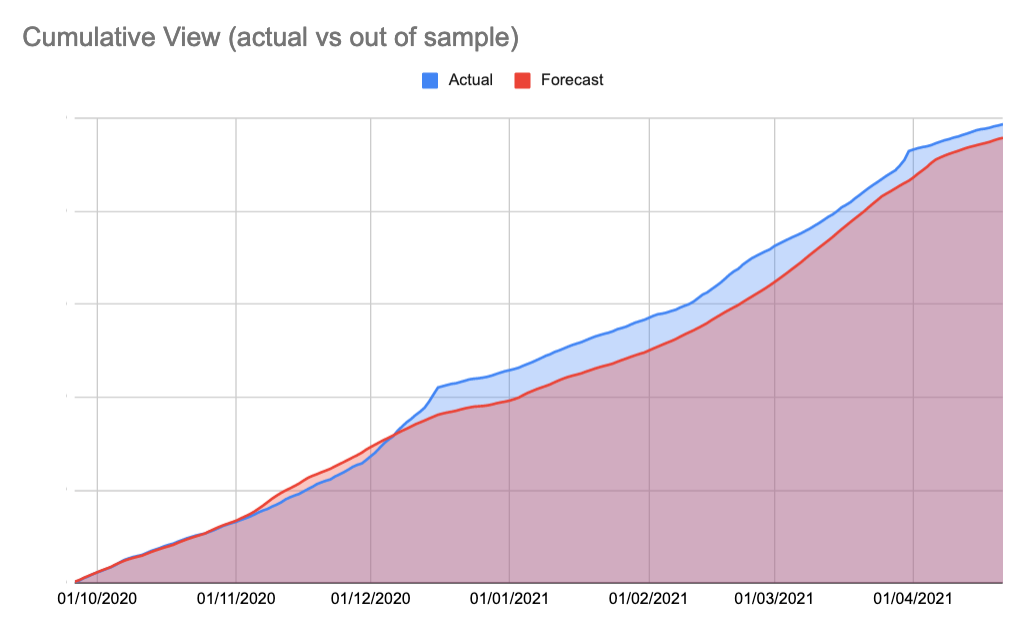
The forecast provides an estimate of what would have happened in the counter-factual world so in order to answer the question you need to compare the totals from what actually happened with the totals from the forecast. In the example above, the real world total is higher but this is mainly because of what happened early in December 2020; you might decide this means the difference in sales because of a different reason and not the one you were originally investigating. Anyone who told you this stuff was going to be simple and easy was lying!
Is this change significant?
The final part is to be able to say whether or not any observed change is meaningful. We all know that no forecast is going to be perfect so we expect that there will always be a difference between what actually happened and a counter-factual forecast. So when you do the analysis and see there is a difference this doesn’t actually tell you very much!
There are two different things that need to be considered here:
- The size of the difference that you have observed
- The uncertainty in the forecast
If the size of the difference is large relative to the uncertainty in the forecast then you can be quite sure that a meaningful change has happened.
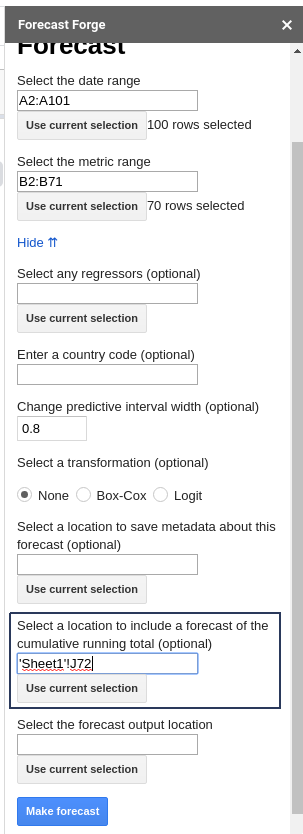
Forecast Forge, either through the sidebar or the FORGE_FORECAST function will
show you the upper and lower bounds for the forecast predictive interval for
each day that you forecast. But, importantly, the daily predictive interval is
not the same as the predictive interval for the total.
This means that if you sum up the lower bound of an 80% predictive interval you will not end up with the lower bound of the 80% predictive interval for the total.
To calculate the correct predictive interval you either need to use the
FORGE_CUMULATIVE_FORECAST function or the relevant part of the sidebar (hidden
behind “Advanced Options”)
Interpreting the results
Consider this example:
![]()
We want to know whether or not the site change on the 14th May made a significant difference or not.
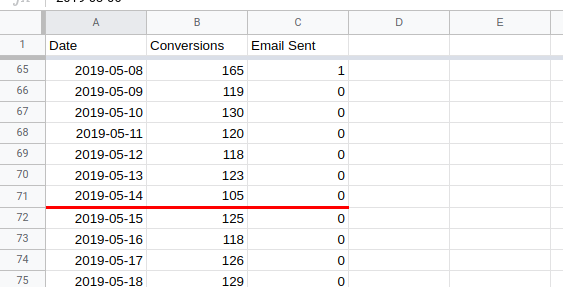
For this exercise start with three columns of data; the date, the number of transactions and a regressor column with whether or not a promo email was sent on that day.
Train a forecast on the data up to the 14th May and then compare the cumulative forecast with the actual cumulative totals (this forecast does not use the email regressor column; we’ll get to that later):
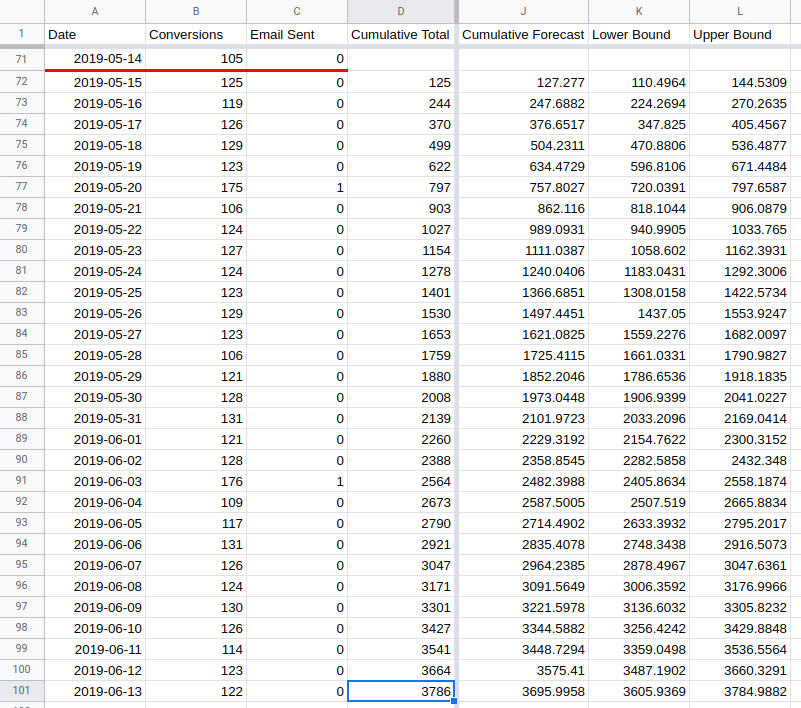
In this case, the actual cumulative total (3786 in cell D101) is higher than the
upper bound for the forecasted total (3785 in cell L101). This means the change
made on the 14th May was a significant improvement.
However….
The default predictive interval width in Forecast Forge is 80%. Which means there is a 10% chance of the actual values being above the interval and a 10% chance they would be below.
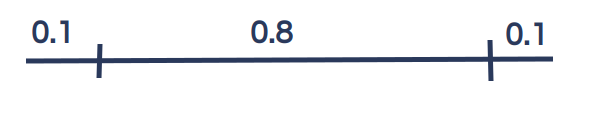
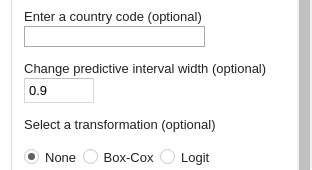
So there is a 90% chance that things actually changed on the 14th May. For some reason people are often obsessed with a 95% chance; if you want to measure at this level instead then change the width of the predictive interval from 0.8 to 0.9 (i.e. 5% above and 5% below):
Rerunning the analysis now gives a different result:

The actual value in cell D101 is within the range between cells O101 and
P101. This is a “non-significant” change (probably a major abuse of stats
terminology here, please don’t yell at me).
This is why having a good forecast is so important. Without the email regressor column the forecasting algorithm cannot understand why there are these semi-regular spikes in transactions. The algorithm concludes that there is just a lot of random variation in daily transactions; then the predictive interval must be wider to allow for this.
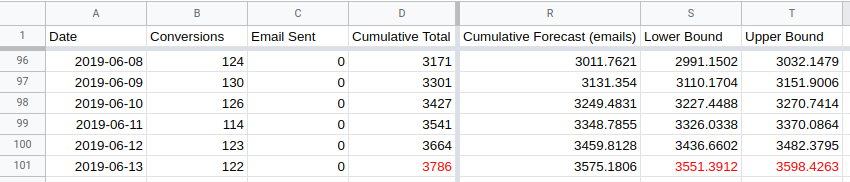
Using the email regressor reduces the width of the predictive interval by a lot. The actual value is waaaay outside the upper bound for the forecast so we can be very confident that something real happened on the 14th May.
You can run a similar analysis on Organic Traffic from Google Analytics or click data from Search Console to see whether or not the new title tag changes have made an important difference for your sites or not.