The Forecast Forge Bet and Six Month Update
Earlier this week I tweeted the below as part of another conversation
My hypothesis with @ForecastForge is that people can make better forecasts using a fairly simple algorithm + their own domain knowledge rather than getting someone else who can make a fancy algorithm but doesn't know the domain
— Richard Fergie (@RichardFergie) March 2, 2021
I thought this would be a good opportunity to unpack my hypotheses about why Forecast Forge is a good/interesting idea. And also a good time to do a quick business update since it has been just over six months since launch.
Data Science and Domain Knowledge
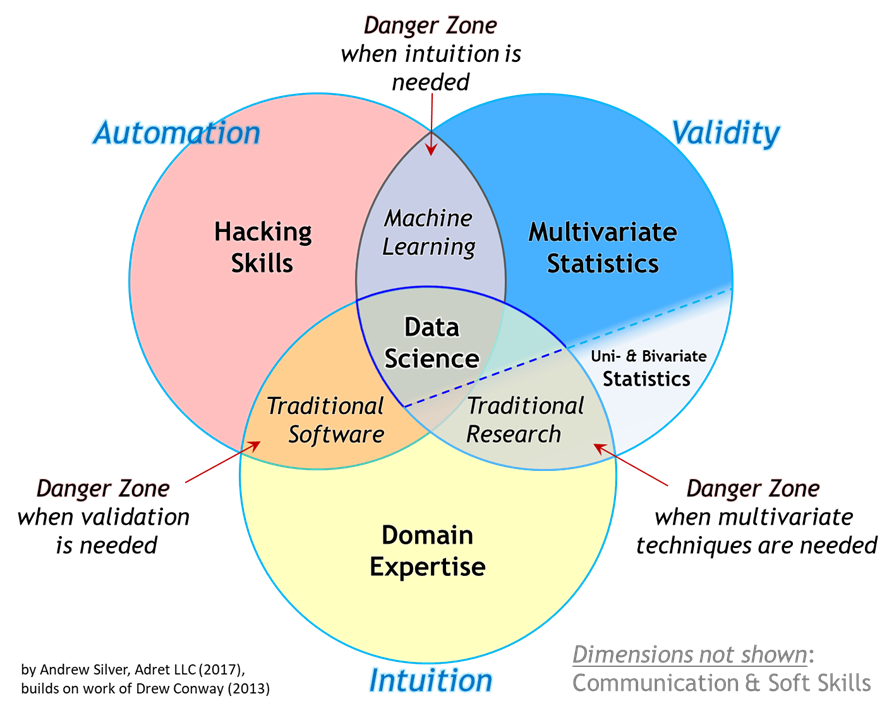
Data Science has always been a combination of three things:
- Machine Learning
- Software Engineering
- Domain Knowledge
More recently, the growth and improvements in deep neural nets has increased the prominence of machine learning and decreased the prominence of domain specific knowledge. For example in late 2016 Google started to use a deep learning algorithm in Google Translate - work on this started in September 2016 and it was performing better than their old algorithm by November 2016. The old algorithm had been developed by language experts over the previous 10 years.
This could just be because of the Jeff Dean effect but other work on large models (e.g. GTP-2/3, Inception-V3, BERT) also shows large neural networks beating more specialised models even at tasks the specialised models were specifically designed for. Most work in this area seems to have been on NLP/text and image classification but it seems reasonable to assume that if Google/Facebook/Amazon were to turn their warehouses full of PhD’s and data centers full of GPUs onto other tasks that we might see similar results in other domains.
Part of the bet I’m making by putting time into Forecast Forge is that, for forecasting, these kind of results are a long way away.
The main reason I believe this is because looking only at the data from the metric you want to forecast is rarely enough to make a good forecast; you also need to think about context and what else is happening in the world.
This is a much harder data challenge than large language models because:
- The data for training such models probably does exist in some cases (Google Analytics traffic + annotations) but the data for making predictions is split across multiple systems; for example there is not a standardised way to make your marketing calendar machine readable.
- Competitive pressures makes it less likely that companies will make their own data available for inclusion in these large models. If you are the large incumbent in your market then making your historical data available for new competitors to use in scenario planning is something that will never happen. Encoding the data in the weights of a large neural net isn’t quite the same as making it available but it is similar!
This means that it seems unlikely anyone will be able to combine data from lots of companies into the forecasting equivalent of Common Crawl or WebText2. And a large “big data” training set is an important pre-requisite for training this type of model.
I’m not saying that working hard to make a great forecasting model isn’t ever going to be worth it. I’m saying that I don’t think it is very likely that there will be a one-model-fits-all solution for this any time soon.
However, I’m pretty sure that engineers working on Google Translate thought the same thing in mid-2016 so this prediction could go wrong very quickly!
Assuming I’m right, a tool to help people make better forecasts needs to enable them to enrich their data before applying a forecasting algorithm. And the algorithm needs to be able to work with this extra information. For someone who isn’t a data scientist any tool to help them do this would end up looking a bit like a spreadsheet anyway so instead of making them work in an incomplete, half-working version of a spreadsheet I decided to go to where people are already working and put Forecast Forge in there.
This has the additional advantage that there are already lots of ways from getting data from wherever it is stored into a spreadsheet and from the spreadsheet into a presentation or Google Data Studio or wherever it goes to next in order to be acted upon.
So in summary:
- I think the best forecasts are not made through using better algorithms but through finding ways to give simpler algorithms more “context” around what else is happening in the world.
- For a non-coder the best and most flexible user interface for this will look a bit like a spreadsheet.
I’m not saying that Forecast Forge gets all of this right at the moment - but the product that does get these things right will look at bit like Forecast Forge. Hopefully that will be me!
Six Month Update
Forecast Forge launched in late August 2020. Now it is early March so I’ve been going slightly more than six months.
Firstly a few things that have gone well:
- People are actually subscribing! Not a huge number of them but it is still kind of a weird/amazing feeling when someone I’ve never spoken to before takes out a subscription
- When I talk to people about what they are doing with Forecast Forge I am often amazed at what they’ve been able to do with it; forecasting things that I would never have thought of and using some really clever regressors too. This gives me HUGE confidence that the spreadsheet approach is the right one; anything else would be too limited by my own imagination. See the case studies page for more on this.
- A lot of users really love the tool. This makes me super happy :-D
- There has been a positive overspill into my consulting work. Previously, I think my consulting offering was too vague and people didn’t know what I could do. My thought process was like “I’m a smart guy, there is probably something I can help most people with once they’ve explained their problems to me” but this is actually terrible positioning for a consultant. Constantly banging on about forecasting is better.
And of course, there are some things that I don’t think have gone so well.
- People do a lot less forecasting than I expected. When I was working in PPC at an agency it felt like I was forecasting or updating forecasts every week but this doesn’t seem to be the experience of a lot of people I’ve talked to. If you’re only making a forecast every six months then obviously the value offered by Forecast Forge is lower.
- The price of Forecast Forge is extremely good value for a piece
of business software. I thought this would make it a complete no-brainer for
people to subscribe and use. But I hadn’t thought about the time it would take
them to learn a new tool and update all their existing forecasting processes.
The cost of the subscription is tiny compared to the time cost of this; I’m
improving the documentation and training materials on this site to help with
but I don’t think this will change the ratio in
cost of tool:cost of timethat much. - Most subscriptions have come after I’ve given people a demo and talked them through a few ways they can use Forecast Forge. I naively expected that most would come via the website with no interaction with me! Selling like this can take up quite a lot of time and represents quite a large opportunity cost for me unless people keep their subscriptions for a long time. But…
- Churn seems fairly high. Within six months 20% of new subscriptions have canceled. I’ve been able to speak to about half of these and I’m satisfied that either it just wasn’t right for them and not what they expected or they only needed it for a short time. This still leaves 10% where I know they were making fairly regular forecasts and still decided that they didn’t want to continue.
- Forecast Forge isn’t very easy to get started with. And people find it
difficult to convert their domain knowledge about a business into a set of
regressor columns. For example, if you know that to forecast a lockdown you need to add a regressor column with
1and0to encode periods of lockdown then this is really easy to do. But it is quite hard to know that that is what you have to do in the first place. Partly this is just because data science is difficult and there is no way around that. But I need to make it as easy or as obvious for people as I can.
A mixed bag of experiences over the first six months, but overall I have really enjoyed the work I’ve done on this and the interactions I’ve had with subscribers, blog readers (yes, including you!) and Twitter followers. This is not going to be my ticket to a massive yacht in the Caribbean any time soon but I am looking forward to seeing what the next six months will bring.